Images

El laboratorio de Genómica Biomédica del IRB Barcelona ha desarrollado un método computacional que identifica las mutaciones causantes del cáncer para cada tipo de tumor.
Este y otros desarrollos del mismo laboratorio buscan acelerar la investigación oncológica y ofrecer herramientas para que los oncólogos puedan elegir el mejor tratamiento para cada paciente.
El trabajo se ha publicado en la revista Nature.
Cada tumor, cada paciente, acumula un elevado número de mutaciones, pero no todas esas mutaciones son significativas para el desarrollo del cáncer. Científicos del IRB Barcelona, liderados por la investigadora ICREA Dra. Núria López-Bigas, han desarrollado una herramienta basada en métodos de aprendizaje automático que evalúa la potencial contribución al desarrollo y la progresión del cáncer de todas las posibles mutaciones en un gen, en un determinado tipo de tumor.
En trabajos anteriores, ya puestos a disposición de la comunidad científica y médica, el laboratorio había desarrollado un método para identificar qué genes son responsables del inicio, el progreso o la expansión del cáncer. “BoostDM va más allá: simula cada posible mutación, dentro de cada gen, para un tipo de cáncer específico y señala cuáles son clave en el proceso canceroso. Esto contribuye a entender cómo se causa un tumor a nivel molecular, y puede ayudar en la toma de decisiones médicas en el momento de elegir la terapia más adecuada para un paciente”, explica la Dra. López-Bigas, jefa del laboratorio de Biomédica Genómica. Además, la herramienta contribuirá a entender mejor los procesos iniciales de la formación de tumores en los distintos tejidos.
La nueva herramienta se ha integrado en la plataforma IntOGen, desarrollada por el mismo grupo y diseñada para ser utilizada por la comunidad científica y médica en proyectos de investigación, y en el Cancer Genome Interpreter, también desarrollado por los investigadores, y más enfocado a la toma de decisiones clínicas por parte de médicos oncólogos.
Actualmente, BoostDM trabaja con los perfiles mutacionales de 28.000 genomas analizados de 66 tipos de cáncer diferentes. El alcance de BoostDM será mayor con el previsible incremento de genomas de cáncer de acceso público.
Un desarrollo basado en la biología evolutiva
Para hallar las mutaciones implicadas en el cáncer, los científicos se han basado en un concepto clave en la evolución: la selección positiva. Las mutaciones que favorecen el crecimiento y el desarrollo del cáncer se encuentran en número más elevado en las distintas muestras, en comparación con aquellas mutaciones que sucederían al azar.
“Partimos de la premisa de que algunas mutaciones solo las llegamos a observar porque las células tumorales con dicha mutación guían el desarrollo del tumor, y nos preguntamos qué distingue a esas mutaciones del resto de mutaciones posibles”, explica el Dr. Ferran Muiños, investigador postdoctoral y primer co-autor del trabajo. “Hacer esto de manera manual sería excesivamente laborioso, pero hay estrategias computacionales que permiten organizar este análisis de manera sistemática y eficiente”, añade.
El método propuesto aprende, a partir de los datos, qué atributos son distintivos de las mutaciones que favorecen el desarrollo del cáncer, lo cual supone información útil para el desarrollo de nuevos enfoques terapéuticos.
Un modelo computacional para cada gen y tipo de cáncer
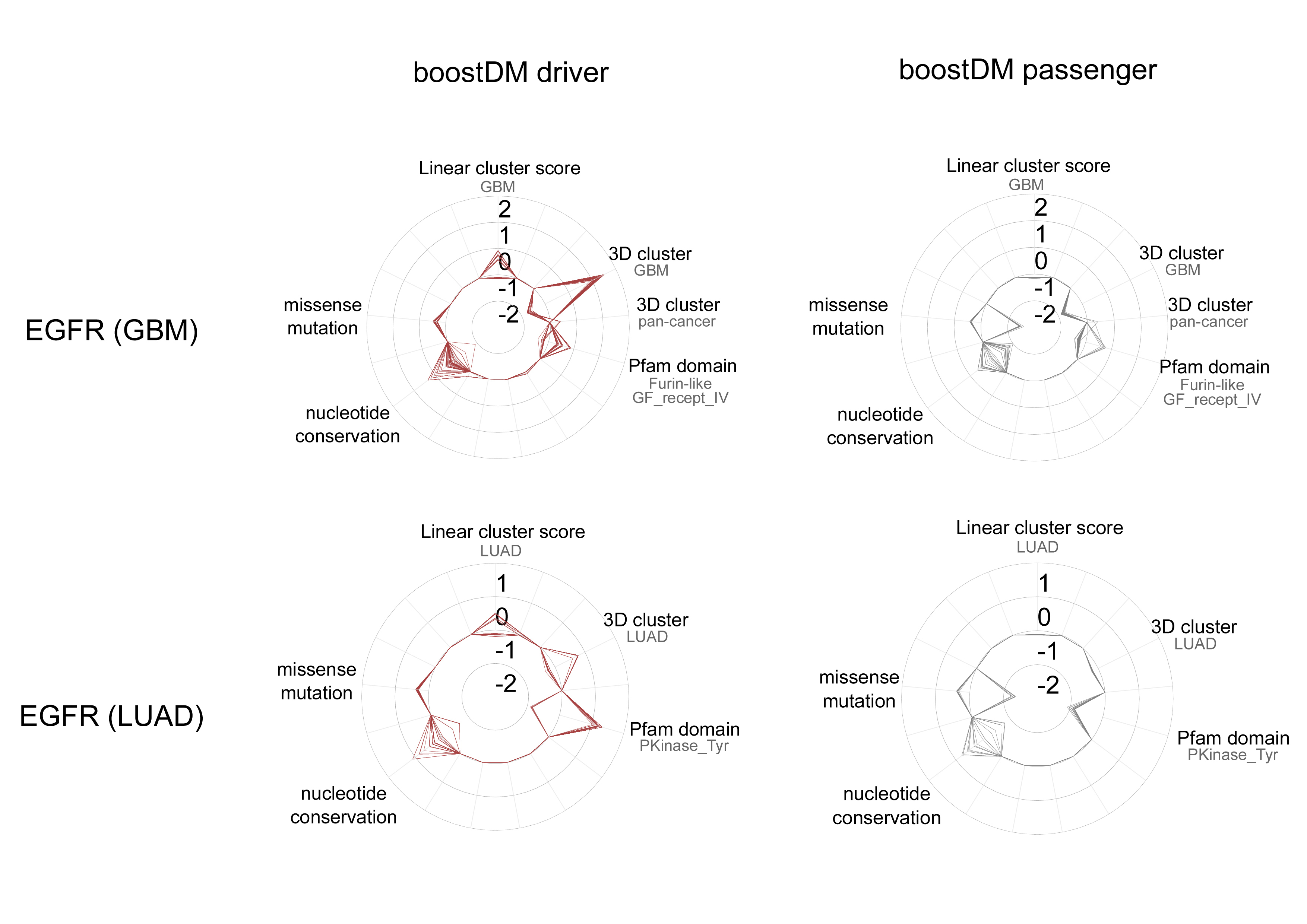
La herramienta que han desarrollado los investigadores ya ha generado 185 modelos para identificar mutaciones en un gen en un tipo de cáncer. Por ejemplo, ha generado un modelo que ha identificado todas las posibles mutaciones que inician la formación del tumor del gen EGFR en algunos tipos de cáncer de pulmón, otro modelo para ese mismo gen en casos de glioblastoma (un tipo de cáncer que se genera en el cerebro), etc.
La técnica que han desarrollado permite generar nuevos modelos, de manera que tengamos modelos para todos los genes de cáncer en los próximos años, a medida que aumenten los datos de tumores secuenciados depositados en el dominio público y se puedan ir incorporando al sistema.
Cuando está desarrollado un modelo, se le puede interrogar sobre cada posible mutación de un gen de cáncer en un tipo de tejido (en un proceso conocido como “mutagénesis de saturación”) y saber si es relevante o no para el desarrollo de la enfermedad. Se genera así un mapa de mutaciones clave que genera un conocimiento muy valioso para la investigación del cáncer, así como para la medicina personalizada del cáncer y la toma de decisiones médicas. Los autores han demostrado que los modelos de predicción como BoostDM son más eficientes y precisos que los enfoques experimentales.
Los autores de este artículo son: el Dr. Ferran Muiños (Doctor en Matemáticas e investigador postdoctoral del laboratorio de Biomédica Genómica y primer co-autor del trabajo), el Dr. Francisco Martínez-Jiménez (anteriormente investigador postdoctoral del laboratorio de Biomédica Genómica, actualmente investigador postdoctoral en la UMC Utrecht y primer co-autor del trabajo), el Dr. Oriol Pich (anteriormente estudiante de doctorado del laboratorio de Biomédica Genómica, actualmente investigador postdoctoral en el Crick Institute en Londres), el Dr. Abel González-Pérez (investigador asociado del laboratorio de Biomédica Genómica, que ha co-dirigido el trabajo) y la Dra. Núria López-Bigas (investigadora ICREA y jefa del laboratorio de Biomédica Genómica del IRB Barcelona, que ha co-dirigido el estudio).
Este trabajo ha sido posible gracias a la financiación recibida por el European Research Council (ERC), la Institució Catalana de Recerca i Estudis Avançats (ICREA), la Asociación Española Contra el Cáncer (AECC), el Ministerio de Ciencia e Innovación, el Fondo Europeo de Desarrollo Regional (FEDER), la Agencia de Gestión de Ayudas Universitarias y de Investigación (AGAUR), el Instituto de Salud Carlos III (ISCIII) y el Barcelona Institute of Science and Technology (BIST).
Artículo de referencia:
In silico saturation mutagenesis of cancer genes
Ferran Muiños, Francisco Martinez-Jimenez, Oriol Pich, Abel Gonzalez-Perez & Nuria Lopez-Bigas
Nature (2021) DOI: 10.1038/s41586-021-03771-1
IRB Barcelona
El Instituto de Investigación Biomédica (IRB Barcelona) trabaja para conseguir una vida libre de enfermedades. Desarrolla una investigación multidisciplinar de excelencia para curar el cáncer y otras enfermedades vinculadas al envejecimiento. Establece colaboraciones con la industria farmacéutica y los principales hospitales para hacer llegar los resultados de la investigación a la sociedad, a través de la transferencia de tecnología, y realiza diferentes iniciativas de divulgación científica para mantener un diálogo abierto con la ciudadanía. El IRB Barcelona es un centro internacional que acoge alrededor de 400 científicos de más de 30 nacionalidades. Reconocido como Centro de Excelencia Severo Ochoa desde 2011, es un centro CERCA y miembro del Barcelona Institute of Science and Technology (BIST).