Images
Una recerca de l’IRB Barcelona proposa una explicació a per què el codi genètic, el diccionari que usen tots els éssers vius per traduir els gens a proteïnes, va deixar de créixer fa 3.000 milions d’anys.
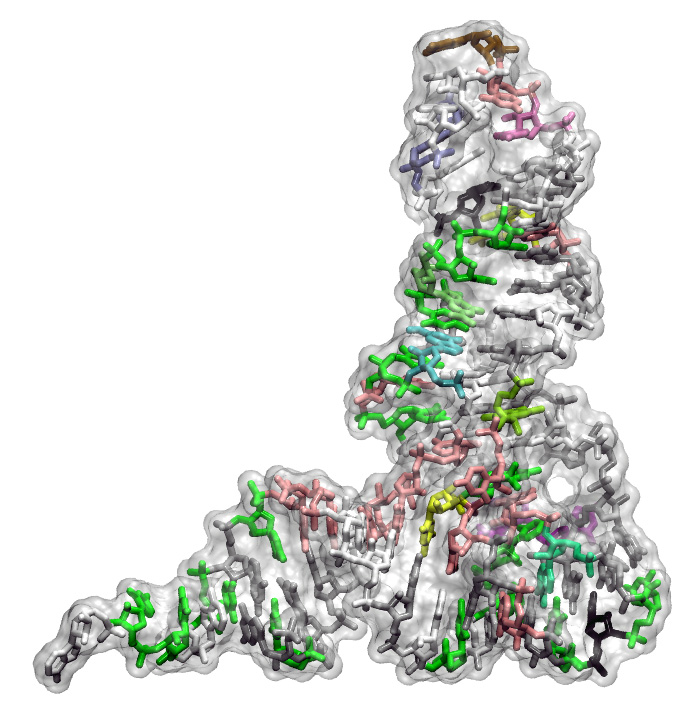
La raó es troba en l’estructura dels ARN de transferència, les molècules centrals en la traducció de gens a proteïnes.
El codi genètic està limitat als 20 aminoàcids amb què es fan les proteïnes, el número màxim que evita caure en mutacions sistemàtiques, fatals per a la vida.
El descobriment pot ser d’utilitat en biologia sintètica.
La natura està en constant evolució, només acotada per les variacions que fan perillar la viabilitat de les espècies. Central en l’evolució de la vida és l’estudi de l’origen i l’expansió del codi genètic*. Un equip de biòlegs experts en aquesta qüestió explica a Science Advances, l’existència d’una limitació que va frenar en sec l’evolució del codi genètic, el conjunt universal de normes que usem tots els organismes de la Terra per traduir les seqüències dels gens dels àcids nucleics (ADN i ARN) a la seqüencia d’aminoàcids de les proteïnes que faran les funcions cel·lulars.
L’equip de científics liderats per l’investigador ICREA Lluís Ribas de Pouplana a l’Institut de Recerca Biomèdica (IRB Barcelona), en col·laboració amb Fyodor A. Kondrashov del Centre de Regulació Genòmica (CRG) i Modesto Orozco de l’IRB Barcelona, ha demostrat que el codi genètic va evolucionar fins a incloure un màxim de 20 aminoàcids i no va poder créixer més per una limitació funcional dels ARN de transferència, les molècules que fan d’intèrprets entre el llenguatge dels gens i el llenguatge de les proteïnes. Aquest fre en el creixement de la complexitat de la vida es va produir fa més de 3.000 milions d’anys, abans que bacteris, eucariotes i arqueobacteris evolucionessin per separat, ja que tots usem el mateix codi per produir proteïnes.
Els autors del treball expliquen que la maquinària per traduir els gens a proteïnes* no pot reconèixer més de 20 aminoàcids perquè els confondria entre ells, el que produiria mutacions constants en les proteïnes i per tant una traducció errònia de la informació genètica “de conseqüències catastròfiques”, destaca Ribas. “La síntesi de proteïnes basada en el codi genètic és l’ànima dels sistemes biològics i és essencial assegurar-ne la fidelitat”, continua l’investigador.
Una limitació marcada per la forma
La saturació del codi genètic té l’origen en els ARN de transferència (tRNA*), les molècules que reconeixen la informació genètica i duen l’aminoàcid corresponent al ribosoma, on es fabriquen les proteïnes encadenant els aminoàcids un rere l’altre segons la informació d’un gen determinat. Ara bé, la cavitat on han d’encaixar-se els tRNA dins el ribosoma imposa a totes aquestes molècules una mateixa estructura similar a una L, que deixa molt poc marge de variació entre elles. “Al sistema li hagués interessat incorporar nous aminoàcids perquè de fet n’usem més de 20 però s’afegeixen per vies molt complexes, fora del codi genètic. I és que va arribar un moment que la Natura no va poder fer nous tRNA que fossin suficientment diferents dels que ja hi havia sense que entressin en conflicte a l’identificar l’aminoàcid correcte. I això va passar quan es va arribar a 20”, exposa Ribas.
Aplicacions en biologia sintètica
Un dels objectius de la biologia sintètica és incrementar el codi genètic, modificar-lo per poder fer proteïnes amb aminoàcids diferents per aconseguir funcions noves. S’usen organismes, com ara bacteris, en unes condicions molt controlades perquè fabriquin proteïnes amb unes determinades característiques. “Però això no és gens fàcil, i la nostra feina demostra que cal evitar aquest conflicte d’identitat entre els tRNA sintètics dissenyats al laboratori amb els tRNA pre-existents per aconseguir sistemes biotecnològics més efectius”, conclou l’investigador.
Aquest treball ha rebut suport del Ministeri d’Economia i Competitivitat, la Generalitat de Catalunya, el Consell Europeu de Recerca (ERC) i la fundació nordamericana Howard Hughes Medical Institute.
Article de referència:
Saturation of recognition elements blocks evolution of new tRNA identities
Adélaïde Saint-Léger, Carla Bello-Cabrera, Pablo D. Dans, Adrian Gabriel Torres, Eva Maria Novoa, Noelia Camacho, Modesto Orozco, Fyodor A. Kondrashov, and Lluís Ribas de Pouplana
Science Advances (29 April 2016). DOI: 10.1126/sciadv.1501860
*INFORMACIÓ COMPLEMENTÀRIA
Per què necessitem el codi genètic?
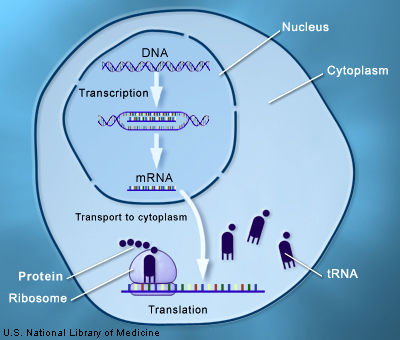
La informació genètica està confinada dins el nucli de la cèl·lula en forma d’ADN. Els gens contenen la informació per fer proteïnes, que són les que duen a terme la gran majoria de les funcions de les cèl·lules, i per tant d’un organisme. Però les proteïnes es produeixen fora del nucli, al citoplasma.
A més, el llenguatge dels gens i el de les proteïnes són diferents. El primer està basat en les lletres de l’ADN, les 4 bases conegudes com a Adenina (A), Timina (T), C (Citosina) i G (Guanina). En canvi, les proteïnes fan servir el llenguatge dels aminoàcids, 20 molècules diferents que combinades formen una àmplia varietat de proteïnes.
El codi genètic és el diccionari que la natura es va “inventar” per poder traduir d’un llenguatge a l’altre.
Com es tradueixen els gens a proteïna?
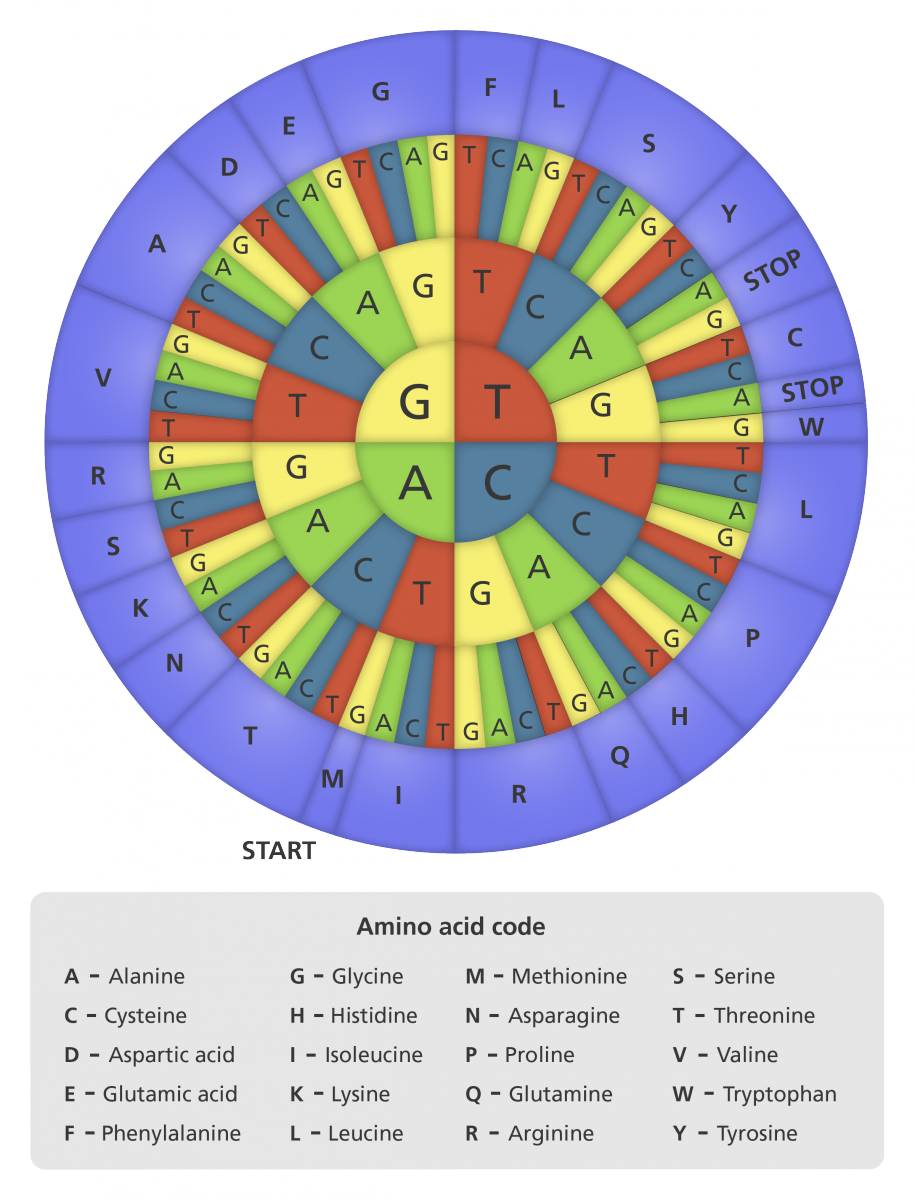
Els gens són seqüències llarguísimes de les quatre bases de l’ADN (ATGCTTTTCACC...), que el codi llegeix de tres en tres, i que s’anomenen triplets o codons (ATG,CTT,TTC,ACC,...). Cada triplet correspon a un aminoàcid. Per exemple, el codó ATG codifica per l’aminoàcid metionina i el codó GCT codifica per l’aminoàcid alanina.
Primer, els gens es copien en un missatger d’ARN (mRNA), un tipus d’àcid nucleic més senzill que l’ADN. Aquest missatger es desplaça fins al citoplasma on es podrà traduir. En aquest procés els protagonistes són el ribosoma, la “fàbrica” de proteïnes, i els ARN de transferència (tRNA).
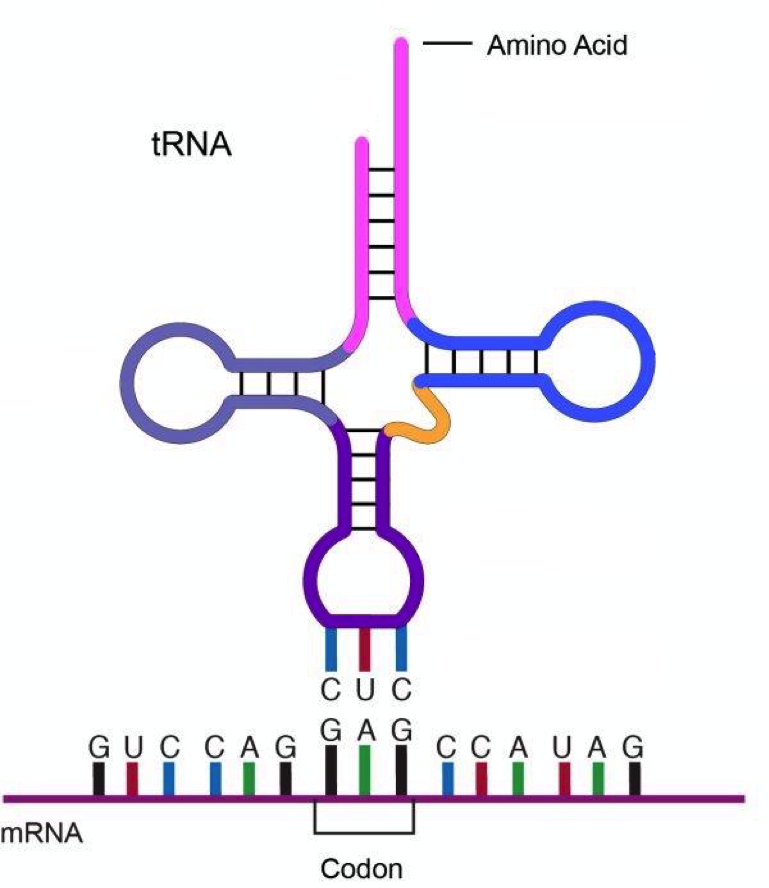
Els tRNAs són la representació física del codi genètic i parlen els llenguatge dels gens i de les proteïnes a la vegada. Aquestes eines fonamentals reconeixen els codons, e.g. GCT, per un extrem, mentre que en l’altre extrem tenen unit l’aminoàcid corresponen al codó, i.e., alanina.
A mesura que el ARN missatger es llegeix al ribosoma, els aminoàcids dels tRNA es van encadenant fins a formar la proteïna codificada en el gen.
IRB Barcelona
L’Institut de Recerca Biomèdica (IRB Barcelona) treballa per aconseguir una vida lliure de malalties. Desenvolupa una recerca multidisciplinària d’excel·lència per curar el càncer i altres malalties vinculades a l'envelliment. Treballa establint col·laboracions amb la indústria farmacèutica i els principals hospitals per fer arribar els resultats de la recerca a la societat a través de la transferència de tecnologia, i du a terme diferents iniciatives de divulgació científica per mantenir un diàleg obert amb la ciutadania. L’IRB Barcelona és un centre internacional que acull al voltant de 400 investigadors de més de 30 nacionalitats. Reconegut com a Centre d'Excel·lència Severo Ochoa des de 2011, és un centre CERCA i membre del Barcelona Institute of Science and Technology (BIST).