Images
Una investigación del IRB Barcelona propone una explicación a por qué el código genético, el diccionario que usan todos los seres vivos para traducir los genes a proteínas, dejó de crecer hace 3.000 millones de años.
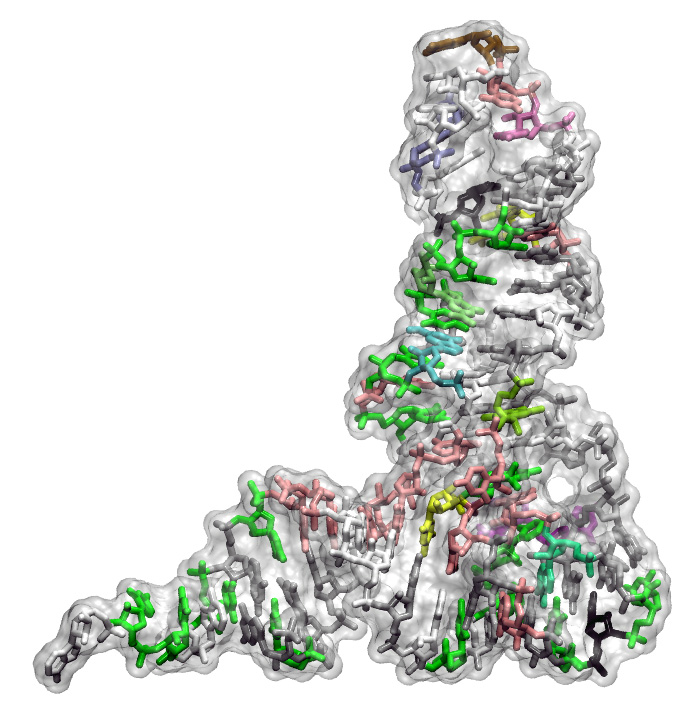
La razón se halla en la estructura de los ARN de transferencia, las moléculas centrales en la traducción de genes a proteínas.
El código genético está limitado a los 20 aminoácidos con que se fabrican las proteínas, el número máximo que evita caer en mutaciones sistemáticas, fatales para la vida.
El descubrimiento puede ser de utilidad en biología sintética.
La naturaleza está en constante evolución, sólo acotada per las variaciones que hacen peligrar la viabilidad de las especies. Central en la evolución de la vida es el estudio del origen y la expansión del código genético*. Un equipo de biólogos expertos en esta cuestión explica en Science Advances, la existencia de una limitación que frenó en seco la evolución del código genético, el conjunto universal de normas que usamos todos los organismos de la Tierra para traducir las secuencias de genes de los ácidos nucleicos (ADN y ARN) a la secuencia de aminoácidos de las proteínas que harán las funciones celulares.
El equipo de científicos liderados por el investigador ICREA Lluís Ribas de Pouplana en el Instituto de Investigación Biomédica (IRB Barcelona), en colaboración con Fyodor A. Kondrashov del Centro de Regulación Genómica (CRG) y Modesto Orozco del IRB Barcelona, ha demostrado que el código genético evolucionó hasta incluir un máximo de 20 aminoácidos y no pudo crecer más por una limitación funcional de los ARN de transferencia, las moléculas que hacen de intérpretes entre el lenguaje de los genes y el lenguaje de las proteínas. Este freno en el crecimiento de la complejidad de la vida se produjo hace más de 3.000 millones de años, antes que bacterias, eucariotas y arqueobacterias evolucionaran por separado, dado que todos usamos el mismo código para producir proteínas.
Los autores del trabajo explican que la maquinaria para traducir los genes a proteínas* no puede reconocer más de 20 aminoácidos porque los confundiría entre ellos, lo que produciría mutaciones constantes en las proteínas y por consiguiente una traducción errónea de la información genética “de consecuencias catastróficas”, destaca Ribas. “La síntesis de proteínas basada en el código genético es el alma de todos los sistemas biológicos y es esencial asegurarse la fidelidad”, continua el investigador.
Una limitación marcada por la forma
La saturación del código tiene el origen en los ARN de transferencia (tRNA*), las moléculas que reconocen la información genética y llevan el aminoácido correspondiente al ribosoma, donde se fabrican las proteínas encadenando los aminoácidos uno tras otro según la información de un gen determinado. Ahora bien, la cavidad donde han de encajarse los tRNA dentro del ribosoma impone a todas estas moléculas una misma estructura similar a una L, que deja muy poco margen de variación entre ellas. “Al sistema le hubiera interesado incorporar nuevos aminoácidos porque de hecho usamos más de 20 pero se añaden por vías muy complejas, fuera del código genético. Y es que llegó un momento en que la Naturaleza no puedo crear nuevos tRNA que fuesen suficientemente diferentes de los que ya había sin que entrasen en conflicto al identificar el aminoácido correcto. Y esto ocurrió cuando se llegó a 20”, expone Ribas.
Aplicaciones en biología sintética
Uno de los objetivos de la biología sintética es incrementar el código genético, modificarlo para poder hacer proteínas con aminoácidos diferentes para conseguir funciones nuevas. Se usan organismos, como bacterias, en unas condiciones muy controladas para que fabriquen proteínas con unas características determinadas. “Pero hacerlo no es nada fácil, y nuestro trabajo demuestra que hay que evitar este conflicto de identidad entre los tRNA sintéticos diseñados en el laboratorio con los tRNA pre-existentes para conseguir sistemas biotecnológicos más efectivos”, concluye el investigador.
Este trabajo ha recibido el apoyo del Ministerio de Economía y Competitividad, la Generalitat de Catalunya, el Consejo Europeo de Investigación (ERC) y la fundación norteamericana Howard Hughes Medical Institute.
Artículo de referencia:
Saturation of recognition elements blocks evolution of new tRNA identities
Adélaïde Saint-Léger, Carla Bello-Cabrera, Pablo D. Dans, Adrian Gabriel Torres, Eva Maria Novoa, Noelia Camacho, Modesto Orozco, Fyodor A. Kondrashov, and Lluís Ribas de Pouplana
Science Advances (29 April 2016). DOI: 10.1126/sciadv.1501860
*INFORMACIÓ COMPLEMENTÀRIA
¿Por qué necesitamos el código genético?
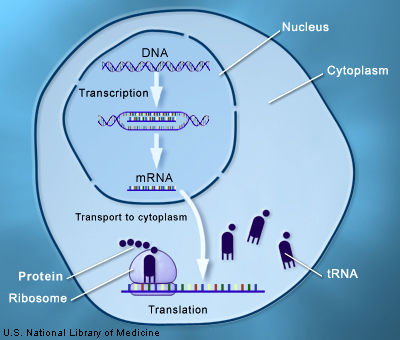
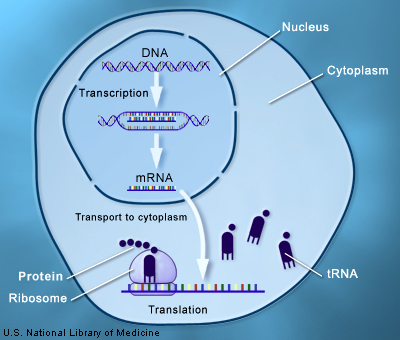
La información genética está confinada dentro del núcleo de la célula en forma de ADN. Los genes contienen la información para hacer proteínas, que son las que llevan a cabo la gran mayoría de las funciones de las células, y por tanto de un organismo. Pero las proteínas se producen fuera del núcleo, en el citoplasma.
Además, el lenguaje de los genes y el de las proteínas son diferentes. El primero está basado en las letras del ADN, las 4 bases conocidas como Adenina (A), Timina (T), C (citosina) y G (guanina). En cambio, las proteínas utilizan el lenguaje de los aminoácidos, 20 moléculas diferentes que combinadas forman una amplia variedad de proteínas.
El código genético es el diccionario que la naturaleza se "inventó" para poder traducir de un lenguaje a otro.
¿Cómo se traducen los genes en proteína?
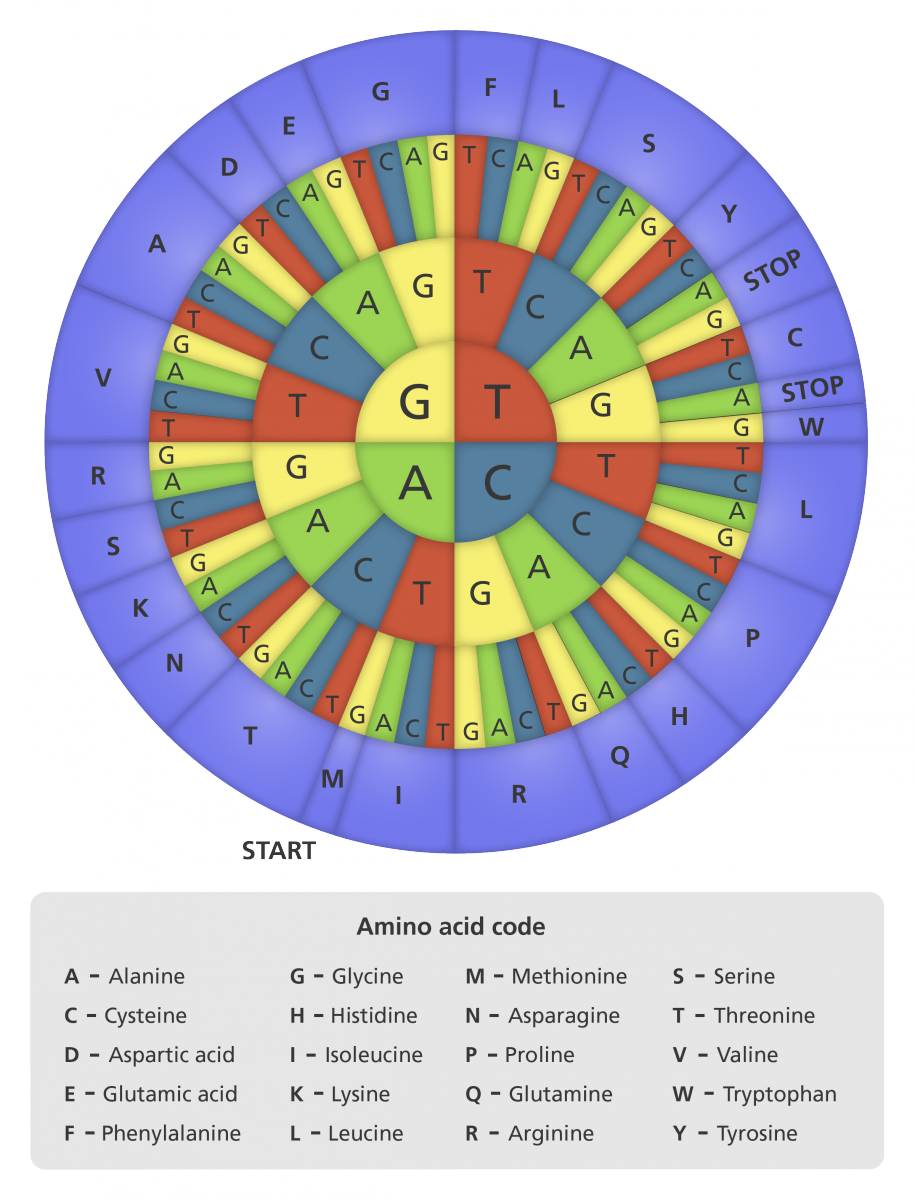
Los genes son secuencias larguísimas de las cuatro bases del ADN (ATGCTTTTCACC...), que el código lee de tres en tres, y que se denominan tripletes o codones (ATG, CTT, TTC, ACC,...). Cada triplete corresponde a un aminoácido. Por ejemplo, el codón ATG codifica para el aminoácido metionina y el codón GCT codifica para el aminoácido alanina.
Primero, los genes se copian en un mensajero de ARN (mRNA), un tipo de ácido nucleico más sencillo que el ADN. Este mensajero se desplaza hasta el citoplasma donde se podrá traducir. En este proceso los protagonistas son el ribosoma, la "fábrica" de proteínas, y los ARN de transferencia (tRNA).
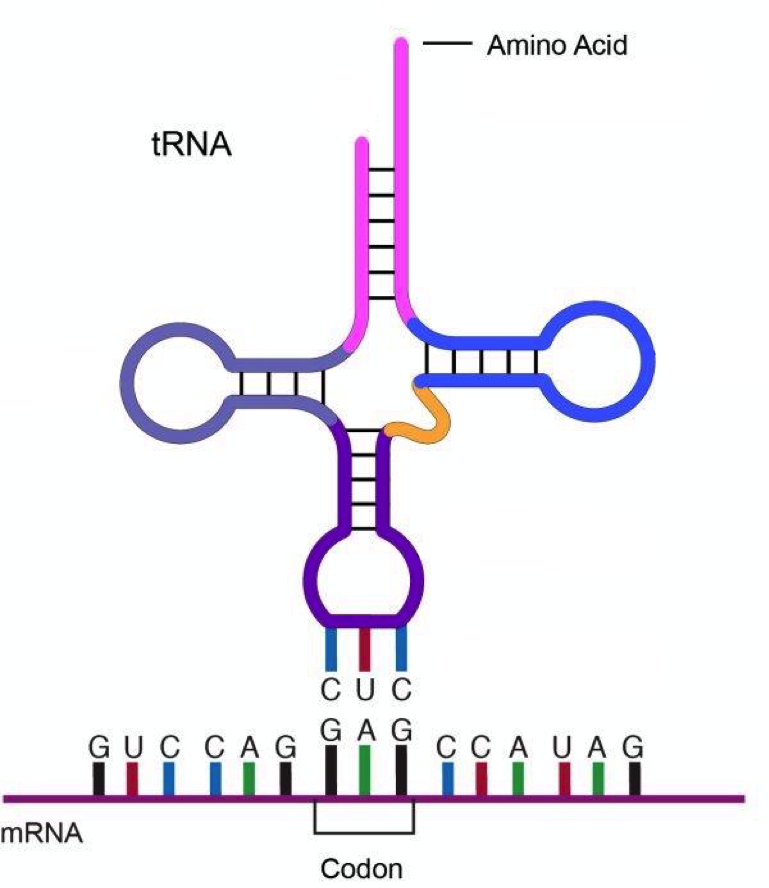
Los tRNAs son la representación física del código genético y hablan los lenguaje de los genes y de las proteínas a la vez. Estas herramientas fundamentales reconocen los codones, e.g. GCT, por un extremo, mientras que en el otro extremo tienen unido el aminoácido corresponden al codón, i.e. alanina.
A medida que el ARN mensajero se lee en el ribosoma, los aminoácidos de los tRNA se van encadenando hasta formar la proteína codificada en el gen.
IRB Barcelona
El Instituto de Investigación Biomédica (IRB Barcelona) trabaja para conseguir una vida libre de enfermedades. Desarrolla una investigación multidisciplinar de excelencia para curar el cáncer y otras enfermedades vinculadas al envejecimiento. Establece colaboraciones con la industria farmacéutica y los principales hospitales para hacer llegar los resultados de la investigación a la sociedad, a través de la transferencia de tecnología, y realiza diferentes iniciativas de divulgación científica para mantener un diálogo abierto con la ciudadanía. El IRB Barcelona es un centro internacional que acoge alrededor de 400 científicos de más de 30 nacionalidades. Reconocido como Centro de Excelencia Severo Ochoa desde 2011, es un centro CERCA y miembro del Barcelona Institute of Science and Technology (BIST).